По нажатию на наименование атрибута в таблице на вкладке Атрибуты, будет открыта дополнительная вкладка <Имя атрибута>, в которой будет отображена детальная информация для анализа данных по этому атрибуту. Для анализа качества данных будут доступны следующие быстрые показатели:
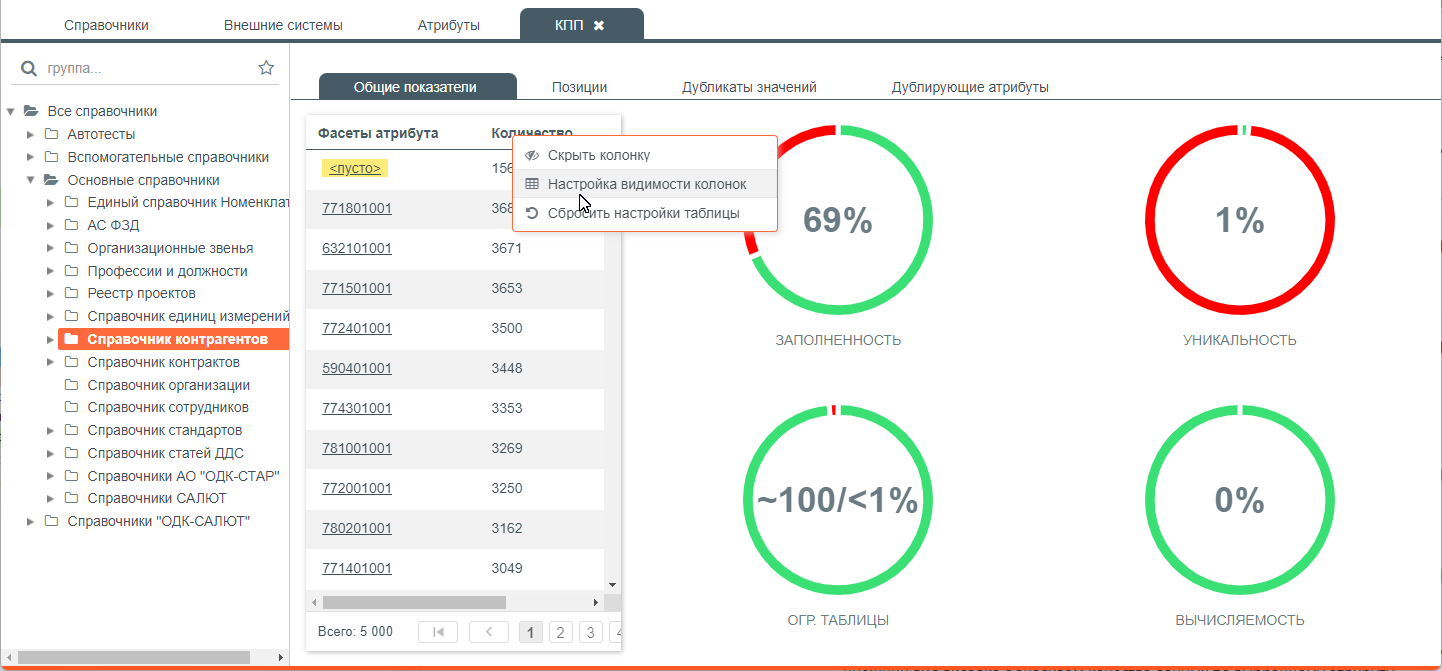
Внешний вид вкладки с анализом качества данных по выбранному атрибуту
Заполненность - позволяет в процентах оценить насколько заполнен атрибут значениями в имеющихся в текущей группе позициях;
Уникальность – позволяет в процентах оценить уникальность значений в позициях. Например, уникальность атрибута “Номенклатурный код” будет максимальной, а атрибута “Тип номенклатуры” минимальный;
Огр. таблицы – позволяет оценить процентах покрытия значений атрибута ограничительными таблицами в дочерних группах;
Вычисляемость – позволяет определить процент значений, которые были вычислены для данного атрибута через формулу, поскольку в некоторых дочерних группах значение может быть вычисляемым, а в некоторых нет.
Кроме быстрых показателей, для выбранного атрибута будут отображены фасеты со значениями этого атрибута. В таблице с фасетами значений можно настроить отображение колонки с количеством значений. Наличие колонок со значениями атрибута и количеством каждого из значений в данных, позволяет выполнять сортировку по любой из колонок. Для анализа качества атрибута в различных разрезах используются дополнительные вкладки:
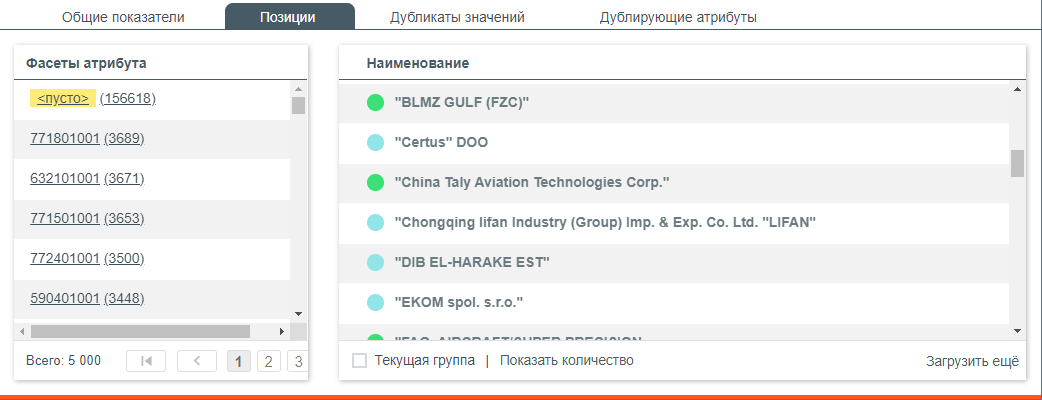
Позиции – на данной вкладке можно посмотреть какие позиции содержат выбранный значение (фасет);
Позиции, содержащие анализируемый атрибут
Дубликаты значений – на данной вкладке можно увидеть какие для атрибута есть потенциальные дубликаты значений, которые различаются различным написанием схожих букв латиницы и кириллицы, или имеют двойные или концевые пробелы;
Дублирующие атрибуты – позволяет отобразить атрибуты, с которыми есть пересечение по значениям атрибутов с другими атрибутами этого же типа данных. Поиск дубликатов выполняется не только по сходству значений в позициях, но и сходству значений в ограничительных таблицах. Дубликаты агрегаций определяются как по сходству ссылок, так и по сходству наименований агрегируемых позиций;
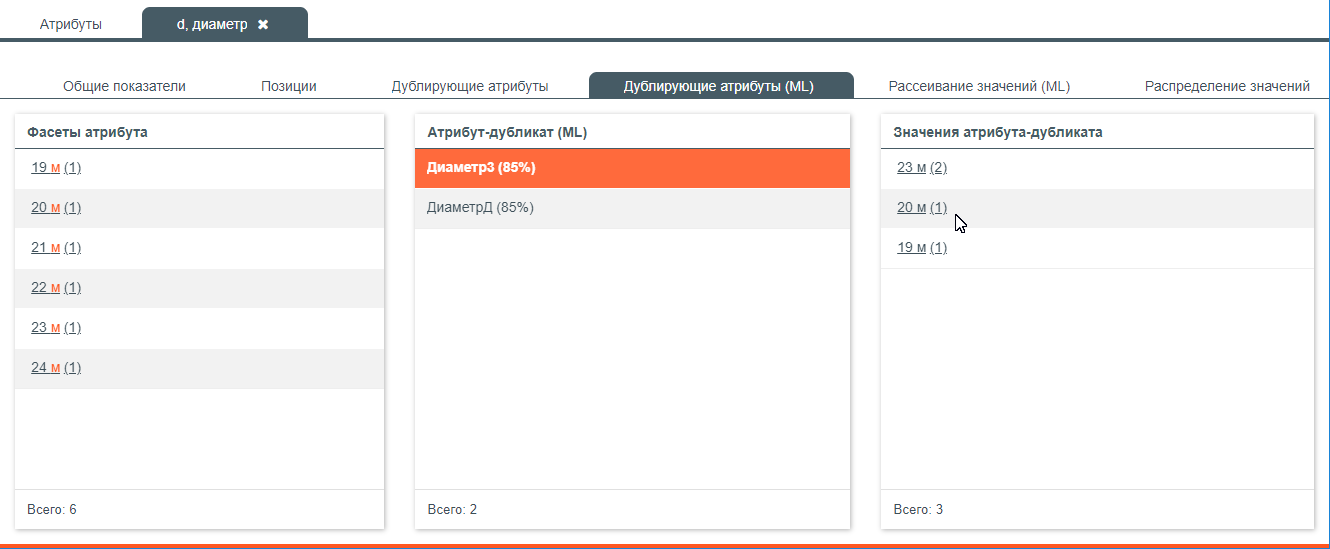
Дублирующие атрибуты (ML) – позволяет определить с помощью подсистемы машинного обучения дубликаты атрибутов со схожими значениями;
Определение атрибутов-дубликатов при помощи машинного интеллекта
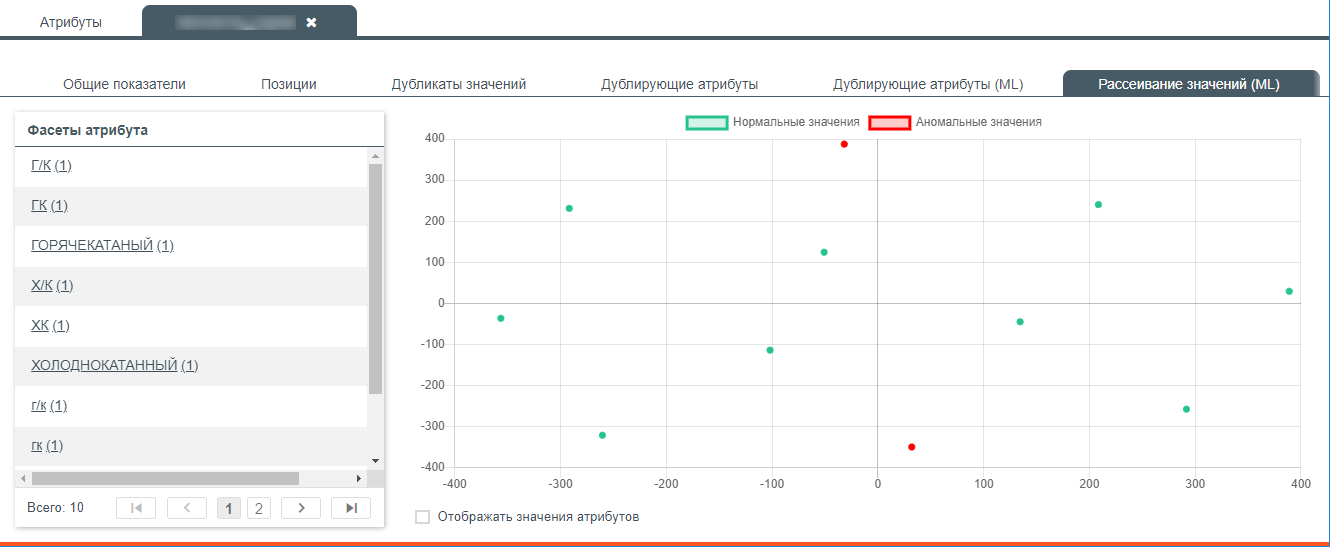
Рассеивание значений (ML) – позволяет увидеть разброс значений в двухмерном пространстве и выделить аномальные значения. Данная вкладка помогает выявить аномальные значения атрибута и группы скопления значений, которые могут семантически иметь один смысл, но записан в значения атрибутов по разному. Например: “Холоднотянутый” как “ХТ”, “Холоднокатанный” как “ХК”;
Рассеивание значений, определенное для атрибута машинным интеллектом
Вкладки Дублирующие атрибуты (ML) и Рассеивание значений (ML) доступны только при использовании подсистемы машинного обучения (Machine Learning, сокращенно ML). Подсистема машинного обучения является дополнительной опцией и в состав базовой MDM не входит.
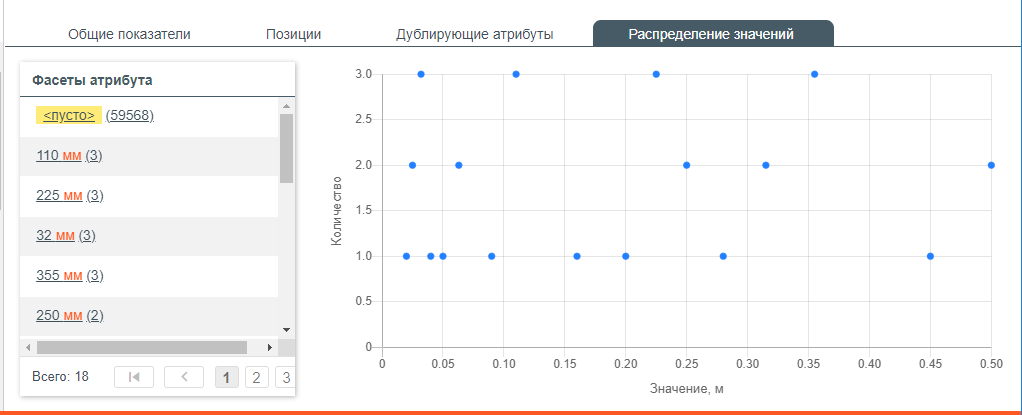
Распределение значений – позволяет для числовых атрибутов на графике увидеть распределение числовых значений и выявить аномальные значения атрибутов.
Распределение значений атрибута
Открытая вкладка с выбранным атрибутом запоминается для текущей группы и при выделении этой или дочерней группы, вкладка с данным атрибутом автоматически будет появляться в панели вкладок.