На вкладке Данные для обучения пользователю доступны следующие действия:
Просмотр данных, на основе которых выполняется обучение;
Быстрый поиск в данных;
Просмотр альтернативных наименований;
Просмотр значений атрибутов, которым обучается подсистема обучения;
Загрузка и выгрузка данных для обучения в CSV;
Загрузка альтернативных наименований из CSV;
Удаление эталонных наименований позиций по их наименованию из CSV файла$
Выбор источника данных.
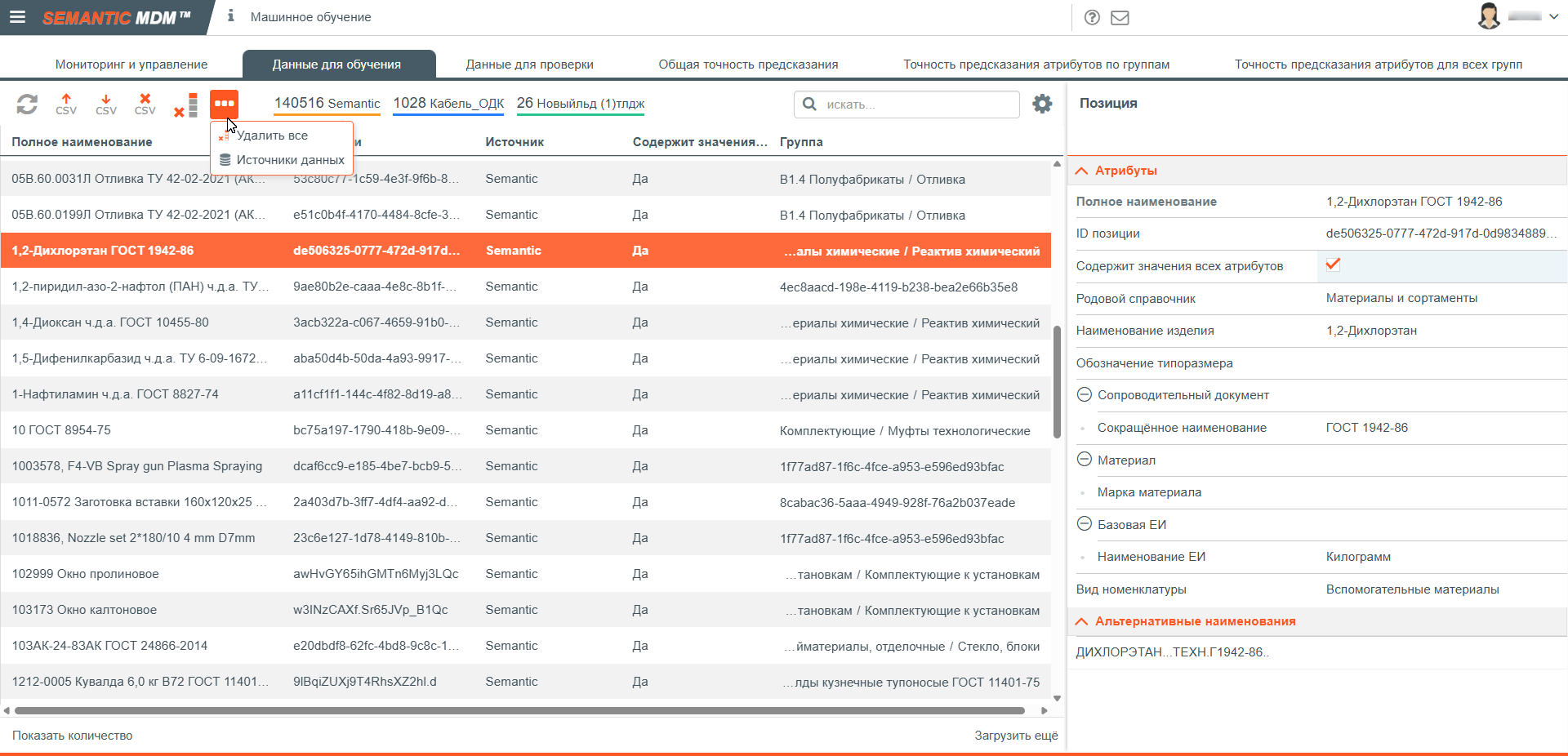
Вкладка Данные для обучения в представлении Машинное обучение
На вкладке присутствует таблица с загруженными справочными позициями, панель инструментов для загрузки / выгрузки данных и карточка с описанием позиции, входящей в состав загруженных данных. Состав колонок таблицы является настраиваемым:
ID образца – внутренний идентификатор позиции, автоматически присваиваемый ML-сервисом;
Полное наименование – уникальное полное наименование позиции;
ID позиции – GUID позиции в Semantic MDM. Идентификатор может отсутствовать, если позиция была загружены не из Semantic MDM;
Источник – наименование источника, из которого было загружена позиция со значениями атрибутов;
Содержит значения всех атрибутов – признак, указывающий, что в пакете изменений содержаться значения всех атрибутов справочной группы;
Группа – короткий путь к справочной группе, состоящий из наименования конечной группы и наименования родительской группы. По щелчку правой кнопкой мыши на группе она будет открыта в новой вкладке браузера;
Таблица может содержать позиции, для которых не указана группа, но которые содержат данные по "сквозным" атрибутам. Для таких позиций в поле Группа выводится системное значение - Группа не задана.
В таблице доступны:
сортировка по колонкам Полное наименование и Источник. По умолчанию включена сортировка по колонке Полное наименование (выполняется по наименованию короткого пути);
фасетная фильтрация доступна по колонкам Группа, Содержит значения всех атрибутов и Источник. При раскрытии диалога с фасетами отображается "худое" дерево групп, с возможностью выбора конечных или промежуточных групп в иерархии. Для быстрой фильтрации, фасеты по группам отображаются также над таблицей сверху;
быстрый поиск по таблице выполняется по следующим данным: GUID, Полное наименование, значение любого атрибута, Альтернативное наименование.
Для работы с данными используются следующие кнопки:
Кнопка
Функция
Обновить таблицу
Загрузить из CSV
Загружает позиции из файла csv. Файл должен содержать четыре колонки со следующими данными: первая колонка (positionName) должна содержать наименование позиции; вторая (propertyName) - наименование предсказываемого атрибута, понятное для пользователя; третья (propertyId) - GUID атрибута в Semantic MDM; четвертая (initialValue) - предсказываемое значение
Экспорт в CSV
Выгружает все позиции со значениями атрибутов в csv, с учетом наложенных фильтров
Удалить через CSV
Позволяет выполнить удаление эталонных наименований позиций с данными для обучения по их наименованию из CSV файла
Удалить
Удаляет выделенные позиции из базы данных машинного обучения. Удаление будет выполнено только после подтверждения операции пользователем.
Удалить все
Удаляет все позиции из базы данных машинного обучения, которые есть в таблице с учетом наложенных фильтров. Удаление будет выполнено только после подтверждения операции пользователем.
Источники данных
Открывает окно Источники данных с таблицей имеющихся источников и кнопками создания и удаления источника. Удаление источника доступно только в случае, если позиции для него отсутствуют.
Для загрузки новых или обновления существующих пакетов переобучения следует:
нажать кнопку Загрузить из csv;
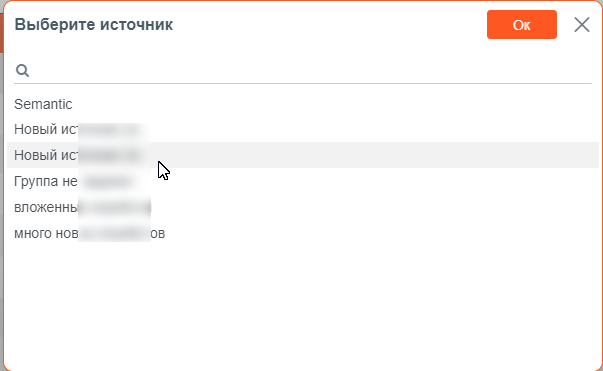
в открывшемся окне Выберите источник установить курсор на наименовании нужного источника данных и нажать кнопку Ок;
Выбор источника данных при загрузке файла csv
в открывшемся окне Подтверждение установить необходимые опции:
Удалить образцы в источнике перед загрузкой - перед загрузкой будут удалены данные для выбранного источника. Используется, если загружаются обновленные данные по всему источнику, а старые данные не актуальны;
Удалить образцы в группе источника перед загрузкой - перед загрузкой будут удалены данные по образцам для группы выбранного источника. Будут удалены данные только по повторно загружаемым группам для выбранного источника;
Обучать загружаемые образцы всем атрибутам группы - для загружаемых образцов будет выполнено машинное обучение по всем атрибутам группы, имеющимся в образцах. Способ учитывает наличие отсутствующих значений для атрибутов.
Выбор способа загрузки данных из csv-файла
После нажатия кнопки Ок будет выполнена загрузка позиций со значениями атрибутов в соответствие с выбранным источником.
При загрузке обновлённых данных по ранее загруженному эталонному наименованию выполняется полная замена старых данных на новые.
Для добавления нового источника данных нужно выполнить следующие действия:
нажать кнопку Источники данных;
в открывшемся окне Источники данных нажать кнопку Создать;
отредактировать наименования источника по умолчанию (Новый источник (номер нового источника));
подтвердить создание нового источника нажав в окне Подтверждение кнопку Ок или отказаться, нажав кнопку Отмена.
Создание нового источника данных
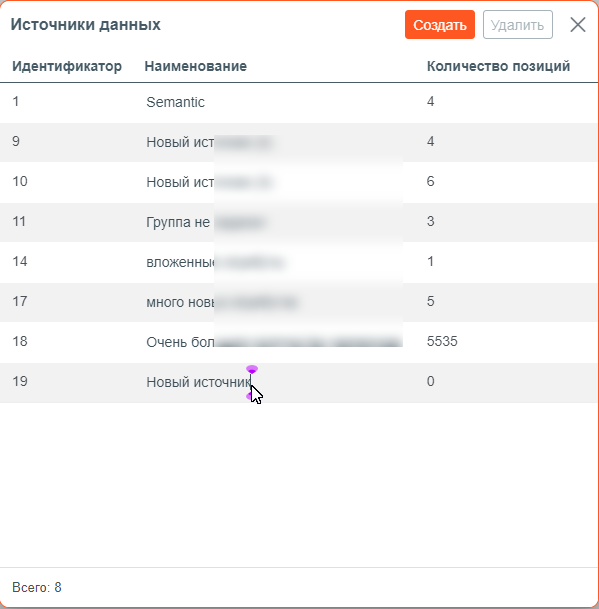
Таблица с источниками содержит следующие колонки:
Идентификатор - идентификатор источника (уникальный в пределах подсистемы ML) устанавливается автоматически;
Наименование - наименование источника;
Количество позиций - количество позиций, имеющихся для данного источника. Устанавливается автоматически при указании источника загрузки данных.
Справа от таблицы с данными располагается карточка выделенной на сетке данных позиции со значениями атрибутов и альтернативными наименованиями. Атрибуты расположены в том же порядке, как их декларации в справочной группе. Для атрибутов связи, наименование формируется через точку с указанием пути до вложенного атрибута. Сортировка вложенных атрибутов на первом уровне идет по агрегации, а на последующих вложенных атрибутах по наименованию. Альтернативные наименования автоматически собираются из заявок пользователей на создание новых позиций в Системе.